Step One in RAG: Building Your First Knowledge Retrieval Pipeline
by Swasthik K,

“How many books have I read this year?” Will ChatGPT be able to answer this at first sight? The answer is NO — because LLMs (like GPT-4, Claude, etc.) are trained on general data up to a certain point in time. They don’t have access to your personal data unless you explicitly give it to them.
So how can we make an LLM read your private notes, documents, or databases and then answer questions from them? 👉 That’s where RAG Retrieval-Augmented Generation comes in.
“RAG is a technique that enhances the capabilities of large language models (LLMs) by integrating them with external knowledge sources.”
Think of it like an open-book exam:
- Without RAG: The model answers from memory (and can hallucinate).
- With RAG: The model opens your notes first, then answers using those notes.
How to implement RAG? Creating RAG from scratch might require complex engineering — but LangChain makes it much easier by providing ready-to-use toolkits.
LangChain is a framework for developing applications powered by LLMs.
A typical RAG application has two main components:
- Indexing → preparing the data (usually offline).
- Retrieval & Generation → answering questions using that indexed data (at runtime).
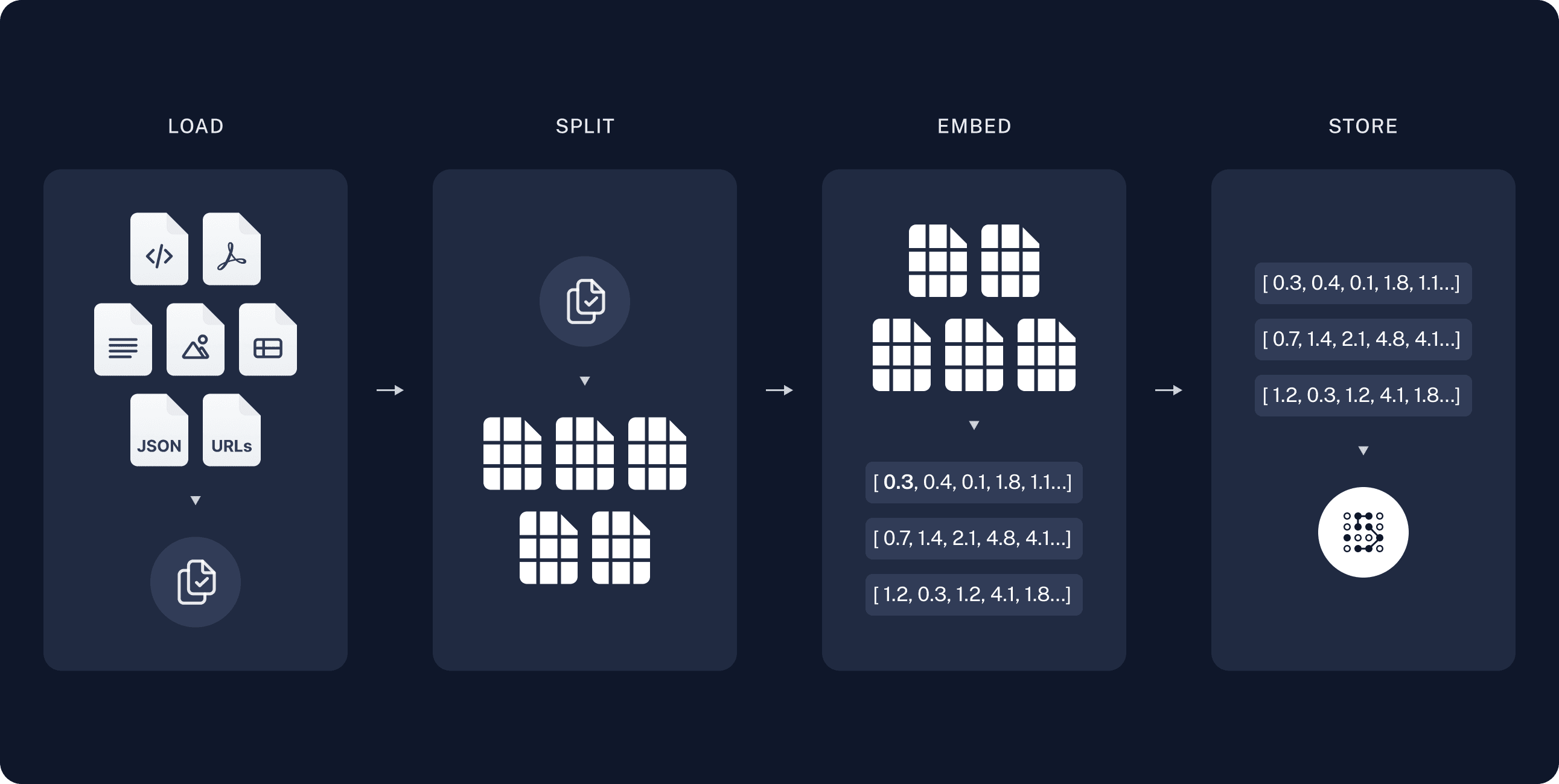
Indexing
- Load the data → Use Document Loaders to bring in data (PDFs, text files, webpages, etc.).
- Split into chunks → Use Text Splitters so large docs become manageable pieces.
- Convert to vectors → Use an Embedding model to turn chunks into numerical vectors that capture semantic meaning.
- Store in Vector Database → Save the vectors into a Vector Store (like FAISS, Chroma, Pinecone, etc.) for fast similarity search later.
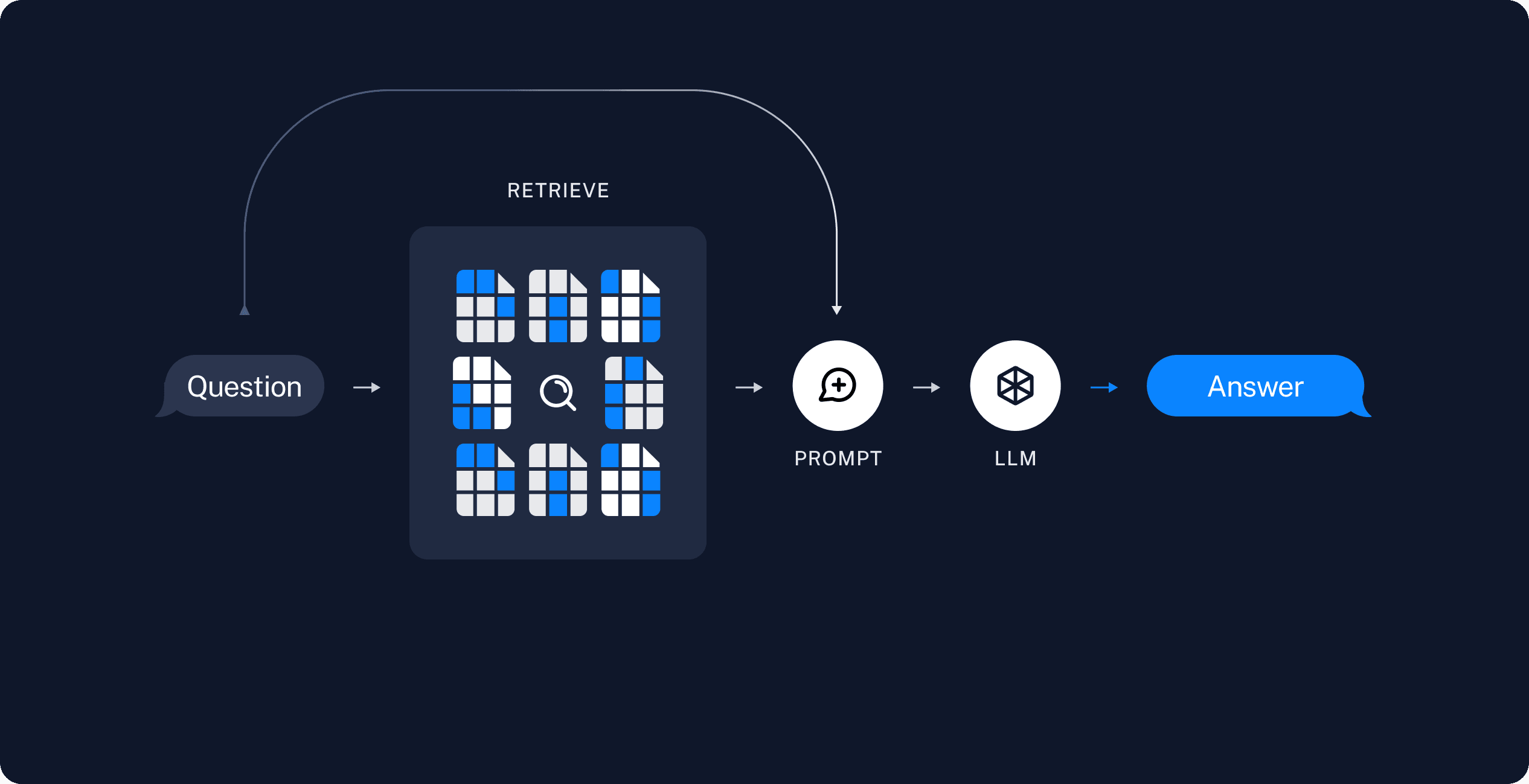
Retrieval and generation
- Retrieve → When a user asks a question, the system uses a Retriever to fetch the most relevant chunks from the Vector Store.
- Build Prompt → A Prompt Template is created that combines the user’s query and the retrieved chunks (context).
- Generate → This prompt is sent to a ChatModel / LLM, which generates the final answer.
That’s enough theory—now let’s quickly build a simple application that takes your Obsidian documents and performs RAG using:
- Chat model from Perplexity
- Embedding model from Hugging Face
- Vector store from Pinecone
👉 Everything in this example uses free tier services.
Prerequisites
- Install Obsidian and set up a vault (your local notes folder).
- Ensure Python is installed on your computer.
Full code example at the end, but for now let’s start with the step-by-step procedure.
Let’s have a basic setup first :
-
Create a folder
-
Open it in VS Code
-
Open terminal
-
Run
python -m venv venv[ this creates a virtual environment ] -
Create files
.env,requirements.txt,main.py -
Paste this inside
dependency.txtPython
python-dotenv langchain langchain_community langchain_huggingface langchain_perplexity langchain_pinecone sentence-transformers -
Run command
pip install -r dependency.txt[ this will install packages ] -
Add these keys inside
.env
PPLX_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" PINECONE_API_KEY = "<YOUR_PINECONE_API_KEY>" PINECONE_HOST = "<YOUR_PINECONE_HOST_URL>" OBSIDIAN_PATH = "<YOUR_OBSIDIAN_VAULT_PATH>" # (eg. "D:\Jons's Vault" ) UPDATE_STORE = False-
To get
PPLX_API_KEY: -
To get
PINECONE_API_KEYandPINECONE_HOST:-
Create pinecone account to recieve
PINECONE_API_KEY -
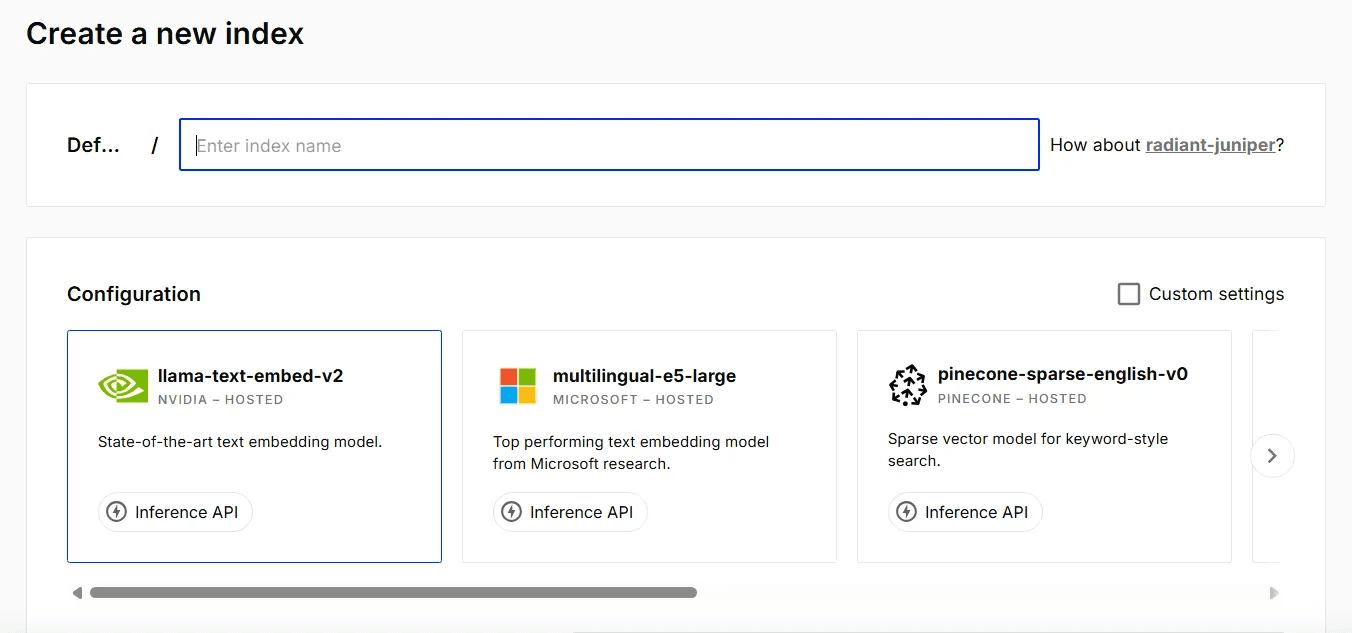
Then Click on “Create Index”

-
Add Index Name
-
Select “Custom settings” in configuration
-
-
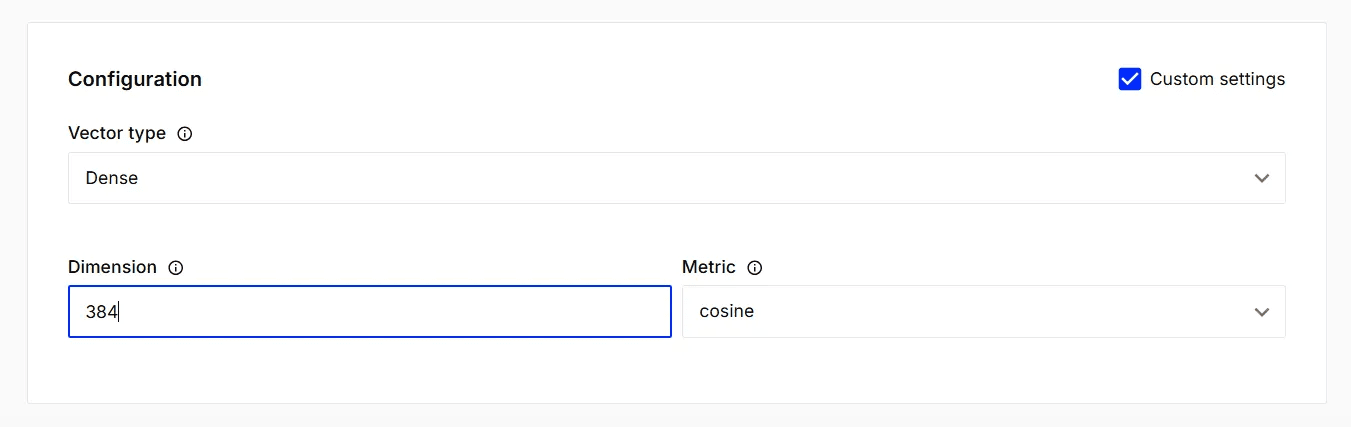
Add dimension 384 and leave the rest of the options default and click “Create Index”
-
Now you will have the host url which you can copy and assign to
PINECONE_HOSTin the.env
-
Now that we’re done with the basic setup, let’s move on to the implementation in main.py.
Step 1 : Import the nessasary packages
Python
from langchain_community.document_loaders import ObsidianLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_pinecone import PineconeVectorStore
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_perplexity import ChatPerplexity
from dotenv import load_dotenv
import os
import sys
import time
load_dotenv()
-
ObsidianLoader→ Loads documents directly from your Obsidian vault. -
RecursiveCharacterTextSplitter→ Splits documents into smaller, manageable chunks. -
HuggingFaceEmbeddings→ Uses free HuggingFace models for embeddings. -
PineconeVectorStore→ Stores and searches embeddings efficiently. -
PromptTemplate→ Creates a template with the retrieved documents and query. -
StrOutputParser→ Formats the output into a clean string. -
ChatPerplexity→ Connects with the Perplexity AI model for answering queries. -
load_dotenv→ Loads environment variables from.envfile.
Step 2 : Define get_vector_store :
Python
def get_vector_store(update_store=False):
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector_store = PineconeVectorStore(
index_name="rag-test",
embedding=embedding_model,
namespace="documents",
pinecone_api_key=os.getenv("PINECONE_API_KEY"),
host=os.getenv("PINECONE_HOST"))
if update_store:
docs = load_documents()
texts = split_documents(docs)
vector_store.add_documents(documents=texts,ids=generate_ids(texts))
print(f"Stored {len(texts)} documents in the vector store")
print("Waiting for documents to be indexed...")
time.sleep(2)
return vector_store
- Uses HuggingFace Embeddings (
all-MiniLM-L6-v2) for vector representation. - Creates a PineconeVectorStore instance with API key & host from
.env. - If
update_store=True:- Loads and splits Obsidian documents.
- Embeds them and stores in Pinecone with unique IDs.
- Waits briefly (2s) for indexing.
- Returns the vector store for DB operations.
Step 3 : Define load_documents :
Python
def load_documents():
loader = ObsidianLoader(os.getenv("OBSIDIAN_PATH"), collect_metadata=False)
docs = loader.load()
if not docs:
print("No documents found in vault. Exiting...")
sys.exit(1)
return docs
ObsidianLoader(...)→ Initializes a loader for the Obsidian vaultcollect_metadata=False→ Ensures only the content of notes is loaded, without extra metadata.loader.load()→ Loads all documents (notes) from the vault into memory.- Return documents → If documents are found, they are returned for further processing (splitting, embedding, etc.).
Step 4 : Define split_documents :
Python
def split_documents(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(docs)
return texts
RecursiveCharacterTextSplitter(...)→ Splits large documents into smaller, manageable chunks of text.chunk_size→ A larger chunk size preserves more context and semantic meaning, while a smaller one gives finer granularity.chunk_overlap→ preserves continuity between chunks so no information is lost at the boundaries.split_documents(docs)→ Splits the loaded documents into chunks.- Return → The resulting list of text chunks (
texts) is returned for later steps (like embedding and indexing).
Step 5 : Define generate_ids :
Python
def generate_ids(texts):
return [f"doc-{i}" for i in range(len(texts))]
- Input → The function receives the list of split text chunks.
- ID Generation → For each chunk, a unique ID is generated in the format
doc-0,doc-1,doc-2, and so on. - Purpose of IDs → These IDs are important when upserting the data into a vector store. you can use complex strategies like UUIDs or hash-based IDs.
Step 6 : Define generate_template :
Python
def generate_template():
return PromptTemplate(
input_variables=["context", "question"],
template="""
Based on the provided context, give a direct and concise answer to the question.
Context: {context}
Question: {question}
Instructions:
- Answer directly and clearly
- Use only information from the context
- Keep response brief and to the point
- Do not add extra suggestions unless specifically requested
Answer:""")
PromptTemplatestructures how the LLM should answer user queries.- Inputs → It accepts two variables:
context→ The retrieved documents or text chunks relevant to the user’s query.question→ The user’s actual question.
- You can modify the wording or add more instructions specific to your use case.
Step 7 : Define main :
-
Firstly, define the
try…exceptblockPython
def main(): try: # ...Your RAG implementation here except Exception as e: print(f"Error : {e}") sys.exit(1) -
Initialize vector store
Python
vector_store = get_vector_store(update_store=os.getenv("UPDATE_STORE", "False").lower() == "true")- Loads the Pinecone vector store.
- If
UPDATE_STORE=True, it will rebuild the vector store with latest docs. - Otherwise, it reuses the saved one.
-
Define user query
Python
query = "How many books have I read this year?"- This is the question the user asks.
- You can replace it with any query.
-
Retrieve similar documents
Python
retrieved_docs = vector_store.similarity_search(query, k=5,namespace="documents")- Uses semantic search to find top 5 most relevant docs (
k=5). namespace="documents"is like a collection name (keeps data organized).
- Uses semantic search to find top 5 most relevant docs (
-
Format retrieved docs into context
Python
context = " ".join([doc.page_content for doc in retrieved_docs])- Joins the content of retrieved docs into one string.
- This becomes context for the LLM.
-
Create prompt template
Python
template = generate_template()- Loads our prompt structure (from earlier steps).
- Ensures model gets input in a consistent format.
-
Initialize ChatPerplexity model
Python
chat = ChatPerplexity( temperature=1, model="sonar", max_tokens=500, api_key=os.getenv("PPLX_API_KEY") )temperature=1→ more creative answers.max_tokens=500→ limit response length.model="sonar"→ choose the Perplexity model (can be changed).api_key→ your Perplexity API key.
-
Build the chain
Python
chain = template | chat | StrOutputParser()- Combines steps:
templateformats input.chatsends it to the model.StrOutputParser()ensures clean text output.
- Combines steps:
-
Run the chain
Python
response = chain.invoke({"context": context, "question": query})- Feeds
contextandqueryinto the chain. - Gets a final AI response.
- Feeds
-
Print the answer
Python
print(f"Response: {response}") -
At last call the
mainPython
main()
Usage :
- Try running
python main.pyand you are expected to get response something like :
Python
The provided context does not specify how many books you have read this year. Therefore, based on the given information, the exact number of books read in 2025 cannot be determined.
- Now try creating file “Books Read” in Obsidian and add some contents as shown below :
Python
2024
- Atomic Habits
- Rich Dad Poor Dad
2025
- The 48 Laws of Power
- Ikigai : the Japanese secret to a long and happy life
- The Alchemist
- The Millionaire Next Door: The Surprising Secrets of America's Wealthy
- Change the
UPDATE_STORE=Trueand re-run the application - Now you are expected to see something like this in the response :
Python
You have read 6 books this year. The books are:
- The 48 Laws of Power
- Ikigai: the Japanese secret to a long and happy life
- The Alchemist
- The Millionaire Next Door: The Surprising Secrets of America's Wealthy
Note:
- Set
UPDATE_STORE = Trueonly when your Obsidian vault content changes and you need to re-insert updated data into the vector store. - Keep it
Falsefor normal query runs (saves time by avoiding re-indexing).
Better to know:
- For the more accuracy and better response consider using OpenAI embedding and chat models.
- You can actully load documents from multiple sources.
References:
- https://python.langchain.com/docs/introduction/
- https://docs.perplexity.ai/getting-started/overview
- https://huggingface.co/sentence-transformers
- https://docs.pinecone.io/guides/get-started/overview
Full Code Example :
Python
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.document_loaders import ObsidianLoader
from langchain_perplexity import ChatPerplexity
from langchain_pinecone import PineconeVectorStore
from dotenv import load_dotenv
import os
import sys
import time
load_dotenv()
def main():
try:
vector_store = get_vector_store(update_store=os.getenv("UPDATE_STORE", "False").lower() == "true")
query = "When do I have to attend Alen's wedding?"
retrieved_docs = vector_store.similarity_search(query, k=5,namespace="documents")
context = " ".join([doc.page_content for doc in retrieved_docs])
template = generate_template()
chat = ChatPerplexity(temperature=1, model="sonar",max_tokens=500,api_key=os.getenv("PPLX_API_KEY"))
chain = template | chat | StrOutputParser()
response = chain.invoke({"context": context, "question": query})
print(f"Response: {response}")
except Exception as e:
print(f"Error : {e}")
sys.exit(1)
def load_documents():
loader = ObsidianLoader(os.getenv("OBSIDIAN_PATH"), collect_metadata=False)
docs = loader.load()
if not docs:
print("No documents found in vault. Exiting...")
sys.exit(1)
return docs
def split_documents(docs):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(docs)
return texts
def generate_ids(texts):
return [f"doc-{i}" for i in range(len(texts))]
def get_vector_store(update_store=False):
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector_store = PineconeVectorStore(
index_name="rag-test",
embedding=embedding_model,
namespace="documents",
pinecone_api_key=os.getenv("PINECONE_API_KEY"),
host=os.getenv("PINECONE_HOST"))
if update_store:
docs = load_documents()
texts = split_documents(docs)
vector_store.add_documents(documents=texts,ids=generate_ids(texts))
print(f"Stored {len(texts)} documents in the vector store")
print("Waiting for documents to be indexed...")
time.sleep(2)
return vector_store
def generate_template():
return PromptTemplate(
input_variables=["context", "question"],
template="""
Based on the provided context, give a direct and concise answer to the question.
Context: {context}
Question: {question}
Instructions:
- Answer directly and clearly
- Use only information from the context
- Keep response brief and to the point
- Do not add extra suggestions unless specifically requested
Answer:""")
main()