Real-Time Event Streaming in Rails with Apache Kafka and Karafka
by Mohammad hussain, System Analyst

Kafka — What is it?
At its core, Apache Kafka is a distributed messaging system that enables different services to communicate with each other efficiently. Kafka follows a distributed log-based architecture, often compared to message queues but designed for higher scalability and durability.
In this post, we’ll break down the essential Kafka concepts—brokers, topics, partitions, producers, and consumers then set up a local Kafka cluster with Docker and integrate it with a Rails application using Karafka.
🔑 Key Kafka Concepts
-
Broker: A broker is simply a Kafka server. It’s responsible for receiving, storing, and serving messages (events). Multiple brokers together form a Kafka cluster.
-
Event: An event (or message) is the data produced to or consumed from Kafka. Events are stored as bytes on the broker’s disk.
-
Producer & Consumer: Producers are services that send (produce) events to Kafka. Consumers are services that read (consume) events from Kafka. A single service can act as both producer and consumer.
-
Topic: A topic organizes messages into categories. Think of it like a folder that holds messages of a specific type, such as payment-details or user-details.
-
Partition: Each topic can be split into partitions to improve throughput. A partition is the smallest storage unit, holding a subset of messages for that topic.
-
Replication Factor: Kafka ensures reliability using replication. A replication factor of 2 means each partition is stored on two brokers—one leader and one replica—ensuring redundancy if a broker fails.
-
Offset: Kafka tracks how far a consumer has read using an offset (like a bookmark). If a consumer crashes, it can resume reading from its last saved offset.
-
Zookeeper: Traditionally, Zookeeper has been used to manage cluster metadata, broker coordination, and leader election. (Note: newer Kafka versions are replacing Zookeeper with the Kafka Raft Metadata mode).
-
Consumer Group: A consumer group is a set of consumers working together. Each partition of a topic is consumed by exactly one consumer in the group, ensuring no duplication while allowing parallel processing.
Understanding Kafka Topics
In Kafka, a topic is like a category or channel where messages (events) are published. Producers send messages to a topic, and consumers subscribe to topics to read those messages.
-
A topic can be divided into partitions, which allow Kafka to scale horizontally.
-
Each partition is an ordered sequence of messages, and within a partition, the order of messages is always preserved.
-
Topics can have replication, meaning their data is copied across multiple brokers for fault tolerance.
-
Consumers don’t remove messages from a topic — Kafka retains them for a configured period (e.g., 7 days by default), so multiple consumers can read the same data at different times.
Think of a topic as a message queue, but unlike traditional queues, Kafka supports multiple independent consumers without deleting the data immediately.
How Events Flow in Kafka
Let’s understand this with two simple scenarios:
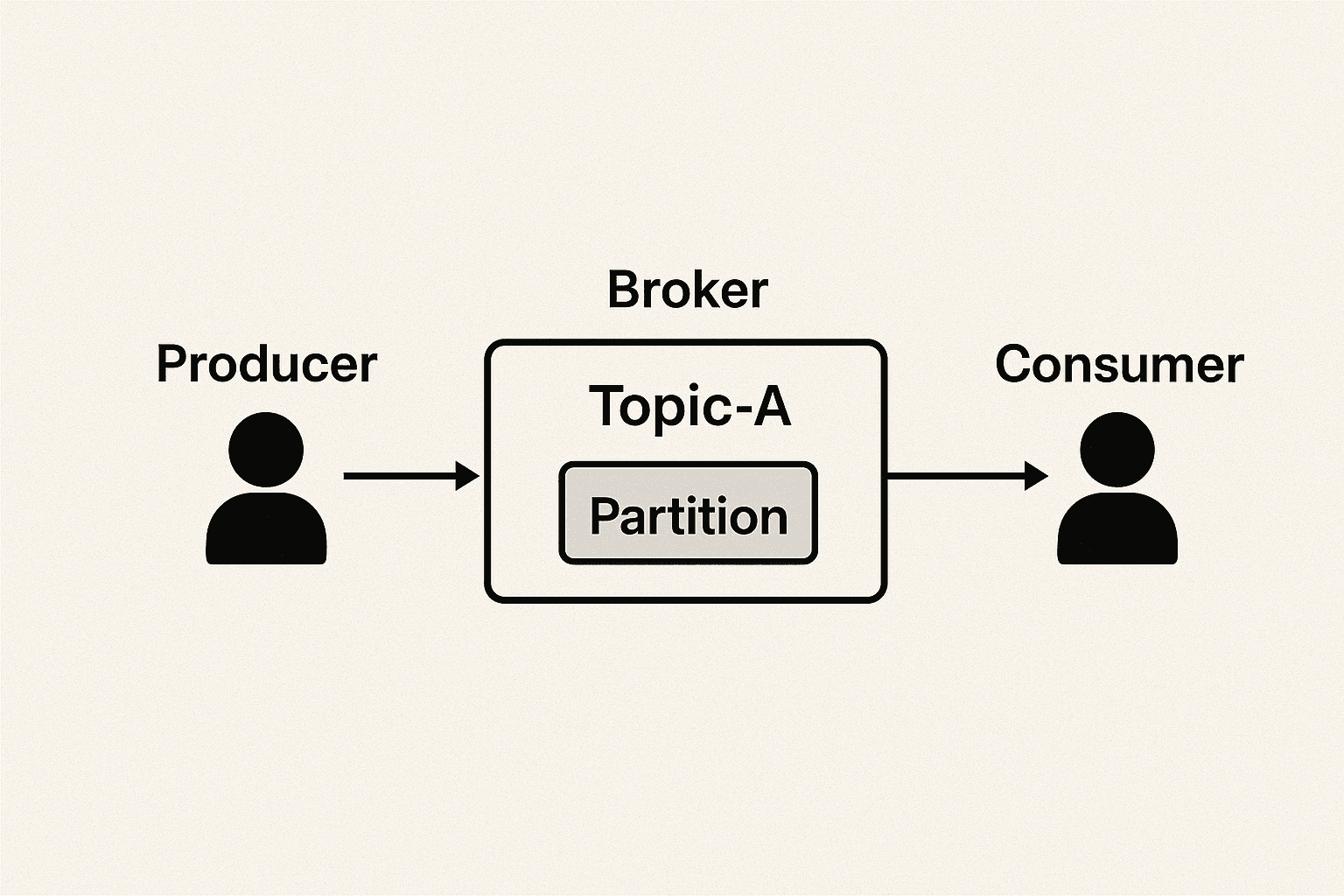
Scenario 1: Single Partition
Imagine we have:
-
1 broker
-
1 topic (Topic-A)
-
1 partition
-
1 producer and 1 consumer
All events generated by the producer are sent to the single partition of Topic-A, which is managed by one broker.
Since there is only one partition, the order of events is preserved exactly as they are produced.
The consumer connected to this topic then reads the events sequentially, ensuring that the data is consumed in the same order in which it was originally written.
This setup is straightforward and guarantees message ordering, but it has limited scalability since everything flows through just one partition.
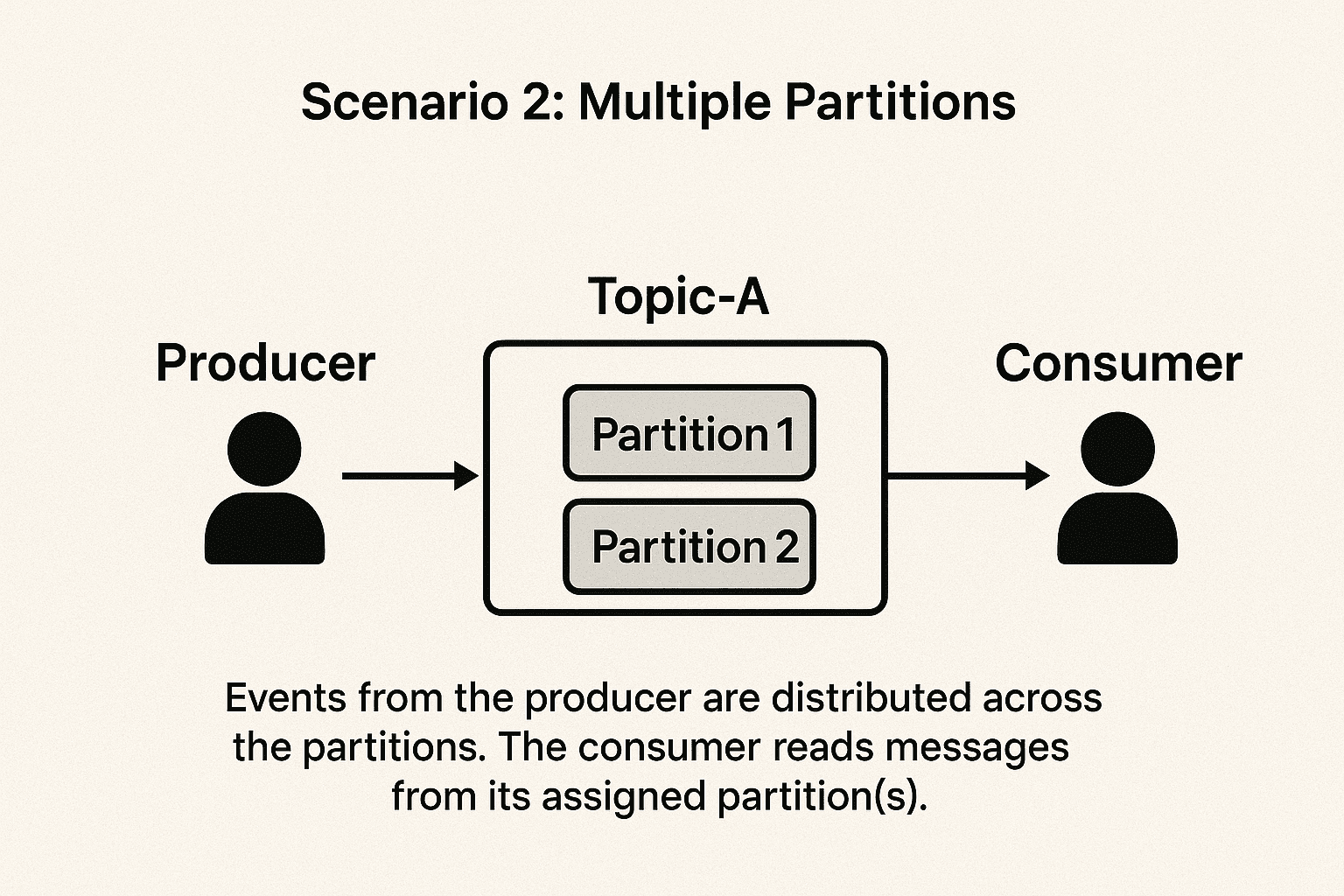
Scenario 2: Multiple Partitions
Now let’s say Topic-A has 2 partitions.
When Topic-A is divided into 2 partitions, the producer’s events are distributed between them.
Each event is written to exactly one partition, and Kafka does not duplicate messages across partitions by default.
This setup increases throughput and enables Kafka to process much larger volumes of data efficiently.
Starting a Kafka Cluster with Docker
Before integrating Kafka with your application, you need a running Kafka cluster. The easiest way to get started is by using the official Docker images.
Pull the Docker image:
docker pull apache/kafka:4.0.0
Start a Kafka container:
docker run -p 9092:9092 apache/kafka:4.0.0
This runs Kafka on port 9092, making it accessible locally.
Installing and Using Karafka with Rails
📖 Karafka Official Documentation
Prerequisite: Ensure your Apache Kafka cluster is up and running before integrating Karafka.
- Add the gem: In your Gemfile, include Karafka:
gem 'karafka'
Then run:
bundle install
- Install Karafka scaffold: Run the install command to generate necessary files:
bundle exec karafka install
This generates a karafka.rb initializer, which configures Karafka and defines routes mapping topics to consumers.
-
karafka.rb — for configuring Karafka and defining topic–consumer mappings
-
app/consumers/example_consumer.rb — a starter consumer
-
app/consumers/application_consumer.rb — base class for custom consumers
Once you’ve installed the karafka gem, you need to configure it with your Kafka cluster and define the topics and consumers.
Example karafka.rb
class KarafkaApp < Karafka::App
setup do |config|
config.kafka = { 'bootstrap.servers': ENV.fetch("KAFKA_SERVERS", "127.0.0.1:9092") }
config.client_id = "my_rails_app"
end
# Subscribe to logging and error monitoring
Karafka.monitor.subscribe(Karafka::Instrumentation::LoggerListener.new)
routes.draw do
# Define topics and assign consumers
topic :products do
consumer ProductsConsumer
# Optional dead-letter queue to catch failed messages
dead_letter_queue(
topic: "products_dlq",
max_retries: 3
)
end
topic :orders do
consumer OrdersConsumer
end
end
end
👉 In this example:
-
We point Karafka to Kafka brokers (bootstrap.servers).
-
Each topic is mapped to a consumer class (e.g., ProductsConsumer).
-
Optional Dead Letter Queues (DLQ) capture failed messages for later debugging.
Example Consumer
class ProductsConsumer < ApplicationConsumer
def consume
messages.each do |message|
data = message.payload
Rails.logger.info "Received product: #{data}"
# Example: Save or update product records in the database
product = Product.find_or_initialize_by(code: data["code"])
product.update!(name: data["name"], price: data["price"])
end
end
end
👉 Here, every time a message is published to the products topic, this consumer will process it.
Example Producer
To send data to Kafka, you can use Karafka’s producer:
def publish_order(order)
Karafka.producer.produce_async(
topic: "orders",
payload: order.to_json
)
end
👉 This sends order data asynchronously to the orders topic.
How It Works
-
Producer: Your Rails app (or another service) publishes messages to a Kafka topic (e.g., orders).
-
Kafka Cluster: Kafka stores these messages in partitions, ensuring ordering within each partition.
-
Consumer: Karafka consumers in your Rails app subscribe to specific topics. Each message is delivered to the matching consumer.
-
Processing & DLQ: The consumer processes the message (e.g., updates the database). If processing fails, the message can be retried or moved into a Dead Letter Queue.
This architecture lets Rails handle real-time event streams, ensuring data flows smoothly between different services.
Thanks for Reading! 🎉
If you’ve made it this far, you’ve successfully taken your first steps into the world of Apache Kafka. You now understand the basics of topics, partitions, producers, and consumers, along with how to set up a cluster and integrate it with Rails using Karafka.
It might seem like a small start, but what you’ve unlocked is powerful—you’re stepping into real-time data streaming, event-driven architecture, and scalable systems that can handle massive workloads. 🚀
Here’s to building applications that don’t just process data, but react to it instantly and unlock new possibilities. ⚡📊