Operating Kafka in Rails with Karafka: Production Architecture, Consumers, and DLQs (Part 2)
by Syed Sibtain, System Analyst
This is Part 2 of a two-part series. If you haven't read it yet, start with Part 1: Introduction and Sync-In, which covers how data enters Rails from external systems (SAP and metadata adapter) and how we set up our Sync-In pipeline.
3.2 Sync-Out — How Data Leaves Rails and Updates the Legacy SQL Server
Once Rails becomes the operational source of truth, the next responsibility is keeping the legacy SQL Server 2009 system in sync. This is where the Sync-Out pipeline comes in.
If Sync-In is about absorbing and validating data, Sync-Out is about publishing clean, normalized, business-ready events from Rails → Kafka → Legacy DB — reliably, idempotently, and without overwhelming the legacy database.
Why Sync-Out Needed a Dedicated Architecture
Sync-Out wasn't a mirror of Sync-In.
It was more fragile, more critical, and far more sensitive to failures.
The Challenges
- SQL Server 2009 could not handle bursts — The legacy database would choke under sudden load spikes
- Multi-step transactional updates — A single business event might touch 4–10 different tables, all within one transaction.
- Duplicate inventory risk — A single retry at the wrong moment could duplicate inventory. Transactions ensured atomicity, but we still needed careful error handling to prevent partial writes
- Strict ordering required — Writes had to remain strictly ordered, especially for receiving operations where sequence mattered
- Full observability needed — During incidents, we had to know exactly what failed and replay it after fixes
The Solution
So Sync-Out became its own pipeline with:
- Rails producers that publish normalized events
- Kafka sync-out topics organized by business domain
- A dedicated adapter service isolated from Rails
- DLQs exclusively for sync-out failures
- Transactional writes with explicit rollback on errors
This is also why only Sync-Out has DLQs — this side is where failures truly matter.
How Sync-Out Works (High-Level Flow)
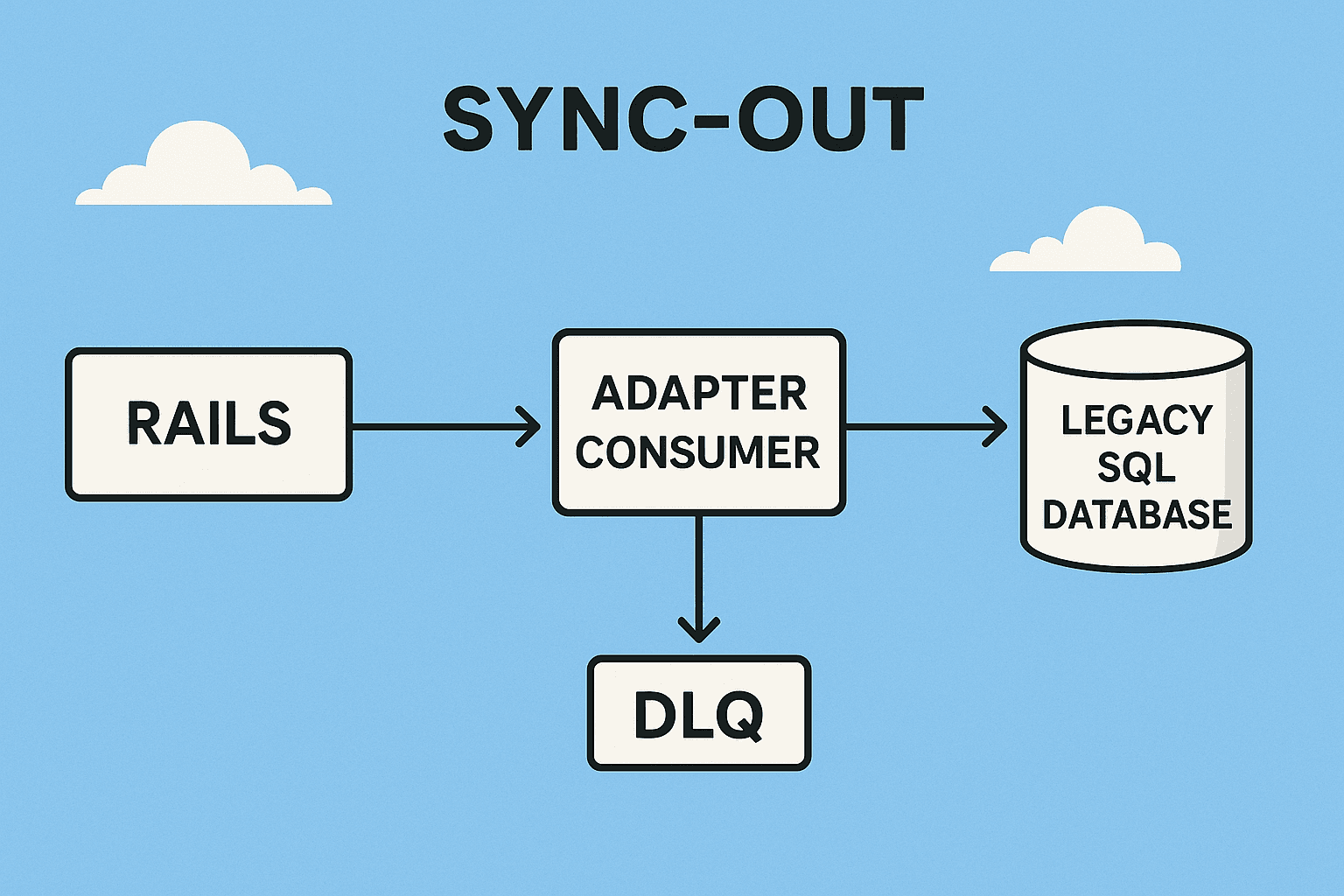
The sequence is simple, but the guarantees are not.
Rails → Kafka → Adapter Consumer → Legacy SQL Server
↑
│
DLQs
1. Rails Publishes Domain Events
Whenever a warehouse operation completes — receiving, putaway, armada close, etc. — Rails publishes a normalized event to Kafka:
Ruby
Karafka.producer.produce_sync(
topic: "legacy_inventory",
payload: InventoryEventSerializer.serialize(record)
)
Each event contains:
operation_type— tells the service what business operation to perform- Normalized payload — clean, business-ready data with all required fields
warehouse_id— identifies which warehouse schema to usesource_event_id— traceability back to Rails- Timestamps — for ordering and debugging
These events describe exactly what changed in Rails.
2. Kafka Stores and Buffers These Events
If SQL Server slows down, Kafka absorbs the back-pressure.
- Rails never waits
- Warehouse operations never stop
3. The Legacy Adapter Consumes and Writes to SQL Server
A dedicated Karafka consumer — running in its own small service — reads sync-out topics and writes to the legacy database using TinyTDS.
This adapter is isolated from Rails so that:
- Rails isn't blocked by SQL Server latency
- The adapter can scale independently
- Legacy writes can be retried or replayed safely
- We can deploy fixes without touching the main app
4. DLQs Capture Any Failure
If the adapter:
- Hits a SQL timeout
- Violates a constraint
- Mis-parses data
- Experiences infrastructure failure
- Encounters a corrupted payload
-> The message moves to a DLQ after max retries.
DLQs were the difference between:
Warehouse operations halted
and
We'll replay the failed ones in 2 minutes.
The Sync-Out Topics
We organized Sync-Out topics by domain — not by table.
Examples:
legacy_receipts— receiving operationslegacy_inventory— stock movements and adjustmentslegacy_putaway— putaway completionslegacy_armada_events— armada operation updates
Each topic represents a business operation, not a technical table.
A single message may update 4–10 different tables in SQL Server.
This mirrors the way the warehouse runs.
The Legacy Adapter Consumer
Here's a simplified version of the pattern we used:
Ruby
class LegacyInventoryConsumer < ApplicationConsumer
class LegacyInventoryConsumerError < StandardError; end
def consume
messages.each do |message|
log_message_payload(message)
process_with_connection(message) do |msg|
# Validate payload structure
result = LegacyInventoryContract.new.call(msg.payload)
if result.success?
# Service object handles the actual write logic
LegacyInventoryService.new(result.to_h[:inventory_event]).call
else
error_message = "Invalid payload for Legacy Inventory: #{result.errors(full: true).to_h}"
Rails.logger.error error_message
raise LegacyInventoryConsumerError, error_message
end
rescue StandardError => e
Rails.logger.error "Legacy inventory sync failed: #{e.message}"
raise
end
end
end
end
The consumer validates with contracts, the service object executes raw SQL, and TinyTdsService handles the connection.
Service Object Pattern
Because SQL Server 2009 didn't play well with ActiveRecord, we wrote raw SQL queries wrapped in explicit transactions. The service object encapsulates all the business logic and orchestrates multiple database operations atomically:
Ruby
class LegacyInventoryService
class LegacyInventoryServiceError < StandardError; end
def initialize(inventory_event)
@event = inventory_event
@warehouse_id = inventory_event[:warehouse_id]
end
def call
TinyTdsService.with_client(@warehouse_id) do |client|
@client = client
client.execute("BEGIN TRANSACTION").do
begin
# Multiple operations within a single transaction
create_receipt_record
update_inventory_levels
update_order_status
create_location_mapping if @event[:location].present?
client.execute("COMMIT TRANSACTION").do
true
rescue StandardError => e
begin
client.execute("ROLLBACK TRANSACTION").do
rescue StandardError
nil
end
Rails.logger.error "[LegacyInventory] Transaction failed: #{e.message}"
raise LegacyInventoryServiceError, e.message
end
end
end
private
def create_receipt_record
result = @client.execute(
"INSERT INTO #{@warehouse_id}.ReceiptDetail
(WarehouseId, ReceiptKey, ItemCode, Quantity, ReceivedDate,
AddDate, AddWho, EditDate, EditWho)
VALUES ('#{@warehouse_id}', '#{@event[:receipt_key]}',
'#{@event[:item_code]}', #{@event[:quantity]},
'#{@event[:received_at]}', '#{@event[:created_at]}',
'#{@event[:created_by]}', '#{@event[:updated_at]}',
'#{@event[:updated_by]}')"
).do
raise LegacyInventoryServiceError, "Failed to create receipt detail" unless result
end
def update_inventory_levels
result = @client.execute(
"UPDATE #{@warehouse_id}.InventoryLocation
SET Quantity = Quantity + #{@event[:quantity]},
EditDate = '#{@event[:updated_at]}',
EditWho = '#{@event[:updated_by]}'
WHERE ItemCode = '#{@event[:item_code]}'
AND Location = '#{@event[:location]}'"
).do
raise LegacyInventoryServiceError, "Failed to update inventory" unless result.positive?
end
def update_order_status
status_code = fetch_status_code(@event[:order_status])
raise LegacyInventoryServiceError, "Invalid status code" if status_code.blank?
result = @client.execute(
"UPDATE #{@warehouse_id}.PurchaseOrder
SET Status = '#{status_code}',
EditDate = '#{@event[:updated_at]}',
EditWho = '#{@event[:updated_by]}'
WHERE OrderNumber = '#{@event[:order_number]}'"
).do
raise LegacyInventoryServiceError, "Failed to update order status" unless result
end
def fetch_status_code(status)
result = @client.execute(
"SELECT Code FROM #{@warehouse_id}.CodeLookup
WHERE ListName = 'OrderStatus' AND Description = '#{status}'"
).each(as: :hash).to_a
result.first['Code'] if result.present?
end
def create_location_mapping
result = @client.execute(
"INSERT INTO #{@warehouse_id}.LotLocationMapping
(WarehouseId, BusinessUnit, ItemCode, LotNumber, Location,
Identifier, Quantity, AddDate, AddWho)
VALUES ('#{@warehouse_id}', '#{@event[:business_unit]}',
'#{@event[:item_code]}', '#{@event[:lot_number]}',
'#{@event[:location]}', '#{@event[:identifier]}',
#{@event[:quantity]}, '#{@event[:created_at]}',
'#{@event[:created_by]}')"
).do
raise LegacyInventoryServiceError, "Failed to create location mapping" unless result
end
end
Why Raw SQL?
SQL Server 2009's limitations forced us to:
- Use TinyTDS gem directly — ActiveRecord's SQL Server adapter had compatibility issues with the legacy database version
- Write raw INSERT/UPDATE queries — Complex multi-table operations needed explicit control
- Manage transactions manually — Some operations required cross-table transactions that ActiveRecord couldn't handle reliably
- Handle status mappings in application code — Legacy stored procedures had side effects we needed to avoid
TinyTDS provides simple and fast FreeTDS bindings for Ruby, giving us direct access to SQL Server's DB-Library API. This was essential for working with SQL Server 2009's constraints and legacy schema patterns.
Transaction Management
Every service object wraps its operations in explicit transactions:
- BEGIN TRANSACTION — Starts the transaction before any writes
- Multiple operations — All related database changes happen within the same transaction
- COMMIT TRANSACTION — Commits only if all operations succeed
- ROLLBACK TRANSACTION — Automatically rolls back on any error
This ensures atomicity: either all operations succeed together, or none of them do. If a service object fails halfway through, the transaction rolls back and the message moves to the DLQ for retry.
Service Object Responsibilities
Each service object handles:
- Transaction management — wraps all operations in BEGIN/COMMIT/ROLLBACK
- Query execution —
execute(...).dopattern for INSERT/UPDATE,each(as: :hash).to_afor SELECT - Business logic — orchestrates multiple database operations in the correct sequence
- Error handling — catches exceptions and ensures rollback even if rollback itself fails
- Status code lookups — fetches codes from lookup tables before writing
- Audit fields — maintains
CreatedAt,CreatedBy,UpdatedAt,UpdatedByfor all writes - Validation — raises custom errors if operations fail or data is invalid
Why Transactions Matter
SQL Server 2009 didn't support much of what we needed natively, so explicit transaction management became essential. A single business event might update 4–10 different tables, and we needed guarantees that:
- All updates succeed together, or none do
- Partial writes never corrupt inventory data
- If any operation fails, the entire transaction rolls back cleanly
- The message can be safely retried from the DLQ after fixing the root cause
Why DLQs Only Exist in Sync-Out
Sync-In failures (SAP or metadata) happen early and are deterministic — we validate, log, and fix them inside Rails.
But Sync-Out was different:
The Sync-Out Failure Modes
- SQL Server could stall unpredictably — Network issues, lock contention, or resource exhaustion
- Connection pool exhaustion was possible — The legacy system had limits we couldn't control
- Deadlocks or lock waits could occur — Multiple operations competing for the same rows
- Legacy constraints required sequential writes — Some tables had triggers that couldn't handle concurrent updates
- Data correctness mattered more than speed — We'd rather delay than corrupt inventory
Implementing DLQs
So we attached DLQs to every Sync-Out topic, with:
Ruby
dead_letter_queue(
topic: "legacy_inventory_dlq",
max_retries: 3
)
This gave us:
- Full visibility into failing messages — we knew exactly what broke
- Guaranteed isolation of corrupted events — bad messages couldn't block good ones
- Zero downtime during legacy outages — warehouse operations continued, we'd catch up later
- Ability to replay after fixing root cause — fix the issue, replay from DLQ, done
During production incidents, DLQs turned hours of debugging into minutes of replay.
Dead-Letter Queues (DLQs): Our Lifeline During Incidents
If Sync-In was predictable, Sync-Out was the place where reality hit us the hardest.
SQL Server 2009 had its own rhythm. Sometimes it was fast, sometimes it locked a table for 3 seconds, sometimes a network blip made inserts fail, and sometimes a malformed payload slipped in due to a previous operator error.
And because Sync-Out writes directly into the legacy system used for reporting and downstream integrations, failure wasn't an option.
That's where DLQs (Dead-Letter Queues) became the most important operational tool in our system.
Why DLQs Only Existed in Sync-Out
Sync-In failures were deterministic:
- SAP sent malformed data → validation fails → logged → fixed → re-sent
- Metadata adapter sent a bad record → it was our system, so we fixed the upstream logic
But Sync-Out failures were different.
SQL Server fails unpredictably:
- Lock waits — tables locked by other processes
- Deadlocks — multiple operations competing for resources
- Timeout expired — classic SQL Server timeout
- Partial network failures — intermittent connectivity issues
- Out-of-order updates — sequence violations
- Payloads missing a lookup reference — data integrity issues
- A table being updated by another system — concurrent access conflicts
- The occasional operator accidentally deleting a reference code — hey, it happens
When this happens, you do not want to block the warehouse.
You want to isolate the bad message, keep the pipeline moving, and fix things later.
DLQs gave us that safety net.
How DLQs Were Configured in Karafka
Karafka makes DLQs surprisingly straightforward.
We added DLQs only to Sync-Out topics:
Ruby
topic :legacy_inventory do
consumer LegacyInventoryConsumer
dead_letter_queue(
topic: "legacy_inventory_dlq",
max_retries: 3
)
end
Our reasoning:
- max_retries: 3 → if SQL Server fails three times, it will probably fail again
- Dedicated DLQ per business domain → easier triage and targeted replay
This setup gave us deterministic, predictable failure handling.
How Failures Flowed
1. Normal flow
Rails → Kafka → Adapter consumer → SQL Server → Success
2. A transient failure
- SQL timeout
- Lock wait
- Network hiccup
Karafka retries → tries again → succeeds → no DLQ needed
3. A persistent failure
After 3 retry attempts:
message ⇒ DLQ topic ⇒ visible in Karafka Web UI
- Warehouse operations keep running
- Consumers continue
- The bad message is isolated
Operational Workflow: How We Handled DLQs
This is where our team's operational discipline came in.
Step 1 — Identify the Failing Message
Using Karafka Web UI:
- Go to Dead Letter Queue section
- Filter by topic (
legacy_inventory_dlq,legacy_receipts_dlq, etc.) - Inspect message payload
- Inspect the attached error, stack trace, and metadata
Karafka Web UI stores:
last_exception.messagelast_exception.classlast_exception.backtrace- Consumer metadata
- Partition/offset
This alone saved hours of guesswork.
We could also check the original payload in Redpanda by looking up the topic and offset, which helped us understand the full context of what was being processed.
Step 2 — Categorize the Failure
We classified failures into 3 categories:
A) Payload issue (most common)
Examples:
- Missing mandatory field
- Invalid status code
- ID mismatch
- Reference record missing
→ Fix payload → Replay
B) Legacy DB issue
Examples:
- SQL Server down
- Deadlock
- Lock wait
- Network timeout
→ Fix infra → Replay all
C) Unexpected bug in our service object
Rare, but happened:
- Wrong SQL
- Wrong assumption
- New schema mismatch
→ Patch code → Redeploy → Replay DLQs
Step 3 — Fix
Depending on category:
- Patch data
- Patch SQL
- Patch code
- Restart legacy DB
- Recreate missing lookup record
- Fix an upstream configuration issue
Because DLQs isolated the failing messages, nothing else was blocked.
Step 4 — Replay
Karafka Web UI made this incredibly easy.
We could replay:
- A single message
- A range of offsets
- An entire DLQ topic
- Or export → edit → re-publish
In cases where business logic required an edit, we'd export the message:
bash
karafka-web dlq export legacy_inventory_dlq > failed.json
Manually fix fields → re-publish to main topic:
bash
cat fixed.json | karafka-web dlq replay legacy_inventory_dlq
This gave us full control.
We could also retry jobs directly from the sync-out service if we needed to reprocess specific operations, or inspect payloads in Redpanda by looking up the topic and offset to verify the original event structure before replaying.
Conclusion
Building a production-ready event streaming system in Rails wasn't about choosing the latest technology—it was about solving real operational problems.
What we learned:
-
Kafka isn't just for scale — It's for isolation, observability, and operational control. When SQL Server stalled, Kafka kept warehouse operations running
-
Sync-In and Sync-Out solve different problems — Sync-In absorbs and validates external data. Sync-Out requires careful transaction management and failure handling. They're not mirrors of each other
-
DLQs are essential, not optional — For systems that write to legacy databases, DLQs turn production incidents from hours of debugging into minutes of replay. They're the difference between "warehouse halted" and "we'll catch up in 2 minutes"
-
Raw SQL isn't a code smell — When working with legacy systems, sometimes the pragmatic choice is the right choice. TinyTDS and explicit transactions gave us the control we needed
-
Observability matters more than you think — Karafka Web UI didn't just show us what failed—it showed us why, with full context. That context saved hours during incidents
The architecture we built wasn't perfect, but it was production-ready.
It handled bursts, isolated failures, scaled horizontally, and gave us the operational tools needed to keep a warehouse running 24/7. Most importantly, it let us sleep at night knowing that when things broke, we could fix them quickly.
If you're building similar systems, remember: the best architecture is the one that solves your actual problems, not the one that looks good on paper.
Vocabulary
This post uses several technical terms and warehouse-specific jargon. Here's a quick reference:
Event Streaming & Messaging
-
Kafka/Redpanda — Distributed event streaming platforms that act as a message broker. They store events in topics and allow multiple consumers to read from them independently.
-
Karafka — A Ruby framework that provides Kafka integration for Rails applications. It handles producers (publishers) and consumers (subscribers) of Kafka messages.
-
Topic — A category or feed name in Kafka where messages are published. Think of it as a channel for specific types of events (e.g.,
legacy_inventory,legacy_receipts). -
Producer — A component that publishes messages to Kafka topics. In our case, Rails acts as a producer when it publishes events about warehouse operations.
-
Consumer — A component that reads and processes messages from Kafka topics. Our legacy adapter consumer reads sync-out topics and writes to SQL Server.
-
DLQ (Dead-Letter Queue) — A special topic where messages that fail processing after maximum retries are sent. This isolates problematic messages and allows manual inspection and replay.
-
Back-pressure — When a downstream system (like SQL Server) slows down, Kafka buffers messages instead of blocking the producer. This prevents the entire system from stalling.
-
Replay — The ability to reprocess messages from a topic, either from a specific point in time or from a DLQ. Essential for recovering from failures.
Data Flow & Architecture
-
Sync-Out — The pipeline that sends data from Rails to the legacy SQL Server system. Data flows: Rails → Kafka → Legacy Adapter → SQL Server.
-
Adapter — A service that translates between different systems. Our legacy adapter converts Rails events into SQL Server writes.
-
Service Object — A Ruby pattern that encapsulates business logic in a single-purpose class. Our service objects handle complex multi-table database operations.
-
Contract Validation — Using a schema validation library (like dry-validation) to ensure message payloads match expected structure before processing. Prevents malformed data from causing errors downstream.
Database & Transactions
-
TinyTDS — A Ruby gem that provides direct access to SQL Server databases using the FreeTDS library. We used it instead of ActiveRecord for legacy database compatibility.
-
Transaction — A group of database operations that must all succeed or all fail together. Ensures data consistency when updating multiple tables.
-
Atomicity — The property that ensures all operations in a transaction complete together, or none do. Prevents partial updates that could corrupt data.
-
Schema — In SQL Server, a schema is a namespace that contains database objects. Our warehouses each had their own schema (e.g.,
warehouse_1,warehouse_2). -
Idempotent — An operation that can be safely repeated multiple times with the same result. Critical for handling retries without creating duplicates.
Warehouse Operations
-
Inventory — The stock of goods in the warehouse.
-
Inventory Adjustments — Adjustments to the inventory, such as stock takes, inventory counts, and inventory transfers.
-
Receiving — The process of accepting incoming goods into the warehouse, verifying quantities, and recording them in the system.
-
Putaway — The process of moving received goods from the receiving area to their storage locations in the warehouse.
-
Armada Operations — Vehicle/fleet management operations for trucks and drivers entering and leaving the warehouse facility.
Technical Concepts
-
Observability — The ability to understand what's happening inside a system through logs, metrics, and traces. Karafka Web UI provides this for our Kafka operations.
-
Legacy System — An older system (in our case, SQL Server 2009) that still needs to be maintained and integrated with, despite its limitations.